之前提到过的 Hadoop 三种模式:单机模式、伪集群模式和集群模式。
单机模式:Hadoop 仅作为库存在,可以在单计算机上执行 MapReduce 任务,仅用于开发者搭建学习和试验环境。
伪集群模式:此模式 Hadoop 将以守护进程的形式在单机运行,一般用于开发者搭建学习和试验环境。
集群模式:此模式是 Hadoop 的生产环境模式,也就是说这才是 Hadoop 真正使用的模式,用于提供生产级服务。
HDFS 配置和启动
HDFS 和数据库相似,是以守护进程的方式启动的。使用 HDFS 需要用 HDFS 客户端通过网络 (套接字) 连接到 HDFS 服务器实现文件系统的使用。
在Hadoop 运行环境 一章,我们已经配置好了 Hadoop 的基础环境,容器名为 hadoop_single。如果你上次已经关闭了该容器或者关闭了计算机导致容器关闭,请启动并进入该容器。
进入该容器后,我们确认一下 Hadoop 是否存在:
hadoop version
如果结果显示出 Hadoop 版本号则表示 Hadoop 存在。
接下来我们将进入正式步骤。
新建 hadoop 用户
新建用户,名为 hadoop:
adduser hadoop
安装一个小工具用于修改用户密码和权限管理:
yum install -y passwd sudo
设置 hadoop 用户密码:
passwd hadoop
接下来两次输入密码,一定要记住!
修改 hadoop 安装目录所有人为 hadoop 用户:
chown -R hadoop /usr/local/hadoop
然后用文本编辑器修改 /etc/sudoers 文件,在
root ALL=(ALL) ALL
之后添加一行
hadoop ALL=(ALL) ALL
然后退出容器。
关闭并提交容器 hadoop_single 到镜像 hadoop_proto:
docker stop hadoop_single docker commit hadoop_single hadoop_proto
创建新容器 hdfs_single :
docker run -d --name=hdfs_single --privileged hadoop_proto /usr/sbin/init
这样新用户就被创建了。
启动 HDFS
现在进入刚建立的容器:
docker exec -it hdfs_single su hadoop
现在应该是 hadoop 用户:
whoami
应该显示 "hadoop"
生成 SSH 密钥:
ssh-keygen -t rsa
这里可以一直按回车直到生成结束。
然后将生成的密钥添加到信任列表:
ssh-copy-id hadoop@172.17.0.2
查看容器 IP 地址:
ip addr | grep 172

从而得知容器的 IP 地址是 172.17.0.2,你们的 IP 可能会与此不同。
在启动 HDFS 以前我们对其进行一些简单配置,Hadoop 配置文件全部储存在安装目录下的 etc/hadoop 子目录下,所以我们可以进入此目录:
cd $HADOOP_HOME/etc/hadoop
这里我们修改两个文件:core-site.xml 和 hdfs-site.xml
在 core-site.xml 中,我们在 标签下添加属性:
<property>
<name>fs.defaultFS</name>
<value>hdfs://<你的IP>:9000</value>
</property>
在 hdfs-site.xml 中的 标签下添加属性:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
格式化文件结构:
hdfs namenode -format
然后启动 HDFS:
start-dfs.sh
启动分三个步骤,分别启动 NameNode、DataNode 和 Secondary NameNode。
我们可以运行 jps 来查看 Java 进程:
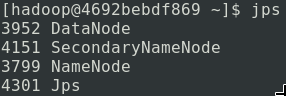
到此为止,HDFS 守护进程已经建立,由于 HDFS 本身具备 HTTP 面板,我们可以通过浏览器访问http://你的容器IP:9870/来查看 HDFS 面板以及详细信息:
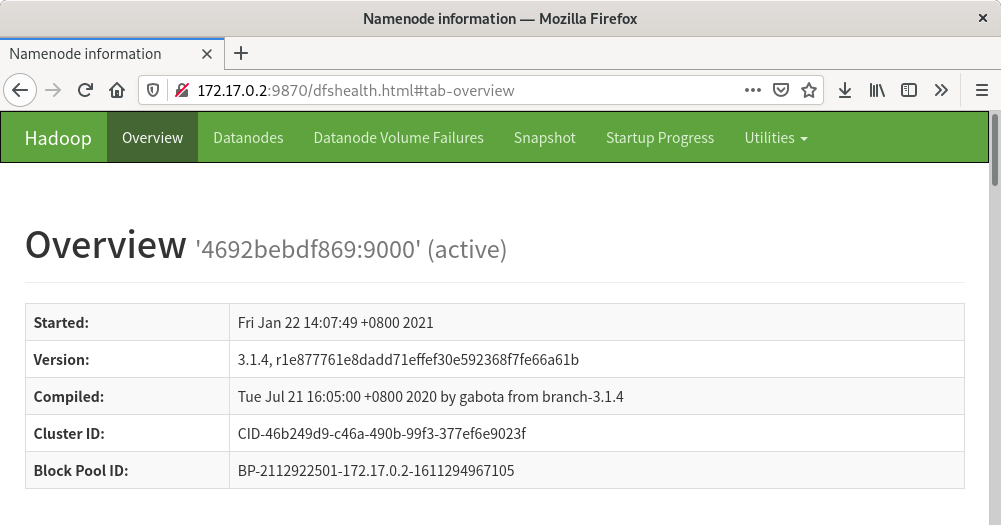
如果出现这个页面,说明 HDFS 配置并启动成功。
注意:如果你使用的不是含有桌面环境的 Linux 系统,没有浏览器,可以跳过这个步骤。如果你使用的是 Windows 系统但是没有使用 Docker Desktop ,那么这个步骤对你来说将难以实现。
HDFS 使用
HDFS Shell
回到 hdfs_single 容器,以下命令将用于操作 HDFS:
# 显示根目录 / 下的文件和子目录,绝对路径 hadoop fs -ls / # 新建文件夹,绝对路径 hadoop fs -mkdir /hello # 上传文件 hadoop fs -put hello.txt /hello/ # 下载文件 hadoop fs -get /hello/hello.txt # 输出文件内容 hadoop fs -cat /hello/hello.txt
HDFS 最基础的命令如上所述,除此之外还有许多其他传统文件系统所支持的操作。
HDFS API
HDFS 已经被很多的后端平台所支持,目前官方在发行版中包含了 C/C++ 和 Java 的编程接口。此外,node.js 和 Python 语言的包管理器也支持导入 HDFS 的客户端。
以下是包管理器的依赖项列表:
Maven:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
Gradle:
providedCompile group: 'org.apache.hadoop', name: 'hadoop-hdfs-client', version: '3.1.4'
NPM:
npm i webhdfs
pip:
pip install hdfs
这里提供一个 Java 连接 HDFS 的例子(别忘了修改 IP 地址):
实例
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class Application {
public static void main(String[] args) {
try {
// 配置连接地址
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://172.17.0.2:9000");
FileSystem fs = FileSystem.get(conf);
// 打开文件并读取输出
Path hello = new Path("/hello/hello.txt");
FSDataInputStream ins = fs.open(hello);
int ch = ins.read();
while (ch != -1) {
System.out.print((char)ch);
ch = ins.read();
}
System.out.println();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
